Unser Wertversprechen ist die effektive und ganzheitliche Begleitung von Innovations- und kollaborativen Kooperationsprojekten.
Digitale Technologie
Unser Wertversprechen ist die schlüsselfertige Umsetzung von digitalen Lösungen auf der Produkt, Service- und Schnittstellen-Ebene.
Digitale Automatisierung
Unser Wertversprechen ist die maximale digitale Automatisierung von repetitiven Aufgaben und Prozessen.
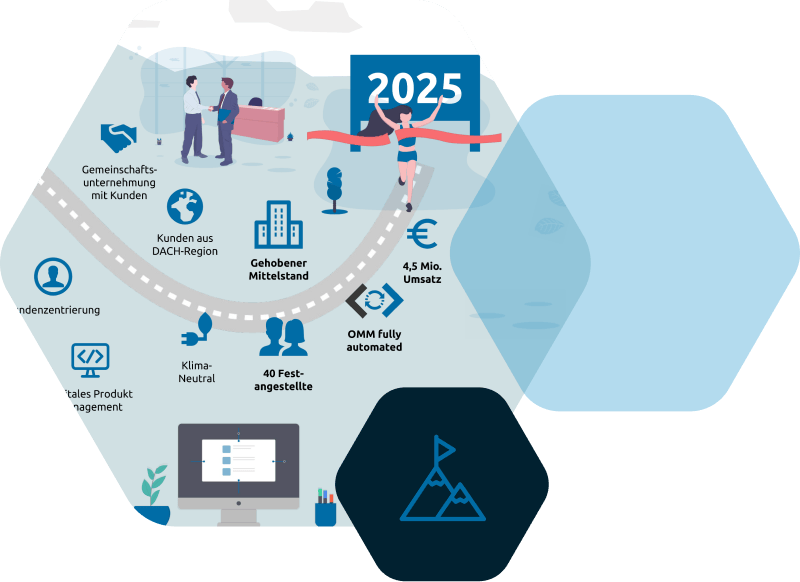
10 Jahre Innovation und Erfolg
Wir feiern unser 10-jähriges Bestehen. Ein Jahrzehnt voller Fortschritt und Erfolg, ermöglicht durch die Unterstützung und das Vertrauen unserer Kunden und Partner. Unsere Vision, Unternehmen dabei zu unterstützen, ihre Innovationskraft zu entfalten, wurde durch unsere Zusammenarbeit Wirklichkeit. Gemeinsam haben wir innovative Ideen in greifbare Erfolge verwandelt.
Unsere Merkmale
Ganzheitlich
Wir agieren in unseren Projekten vollständig End-2-End.
Technologie-begeistert
Wir besitzen eine Leidenschaft für neue Technologien.
Lernend
Wir sind offen und bereit, jeden Tag dazu zu lernen.
Kundenzentriert
Wir stellen die Bedürfnisse unserer Kunden in den Mittelpunkt.
Branchenübergreifend
Wir sind in über 15 Branchen aktiv und vernetzen unsere Kunden.
Unabhängig
Wir sind organisatorisch gewachsen und inhabergeführt.
Ihre Ziele
Werte für Kunden schaffen
Innovationen auf Produkt- und Geschäftsmodell-Ebene am Markt für mein Unternehmen etablieren.
Handlungsspielraum erweitern
Mit dem Einsatz neuer Technologien Geschäftspotentiale in meinem Unternehmen ermöglichen.
Effizienzen heben
Geschäftsprozesse zukunftsfähig in meinem Unternehmen optimieren, standardisieren & automatisieren.
News, Insights und mehr
Verpassen Sie keine Neuigkeiten mehr uns! Klicken Sie auf ‚Jetzt folgen‘, um stets am Puls unseres Wissens und unserer Updates zu bleiben. Schließen Sie sich unserer Community an, ganz nach unserem Motto: Gemeinsam digital wachsen!
Tauchen Sie ein in die Welt der Innovation! Abonnieren Sie INNOpulse, unseren exklusiven Podcast, der Innovationsmanagern frisches Wissen und inspirierende Denkanstöße bietet. Hören Sie jetzt rein und lassen Sie sich von spannenden Gesprächen und wegweisenden Ideen inspirieren.